Accuracy on financial handwriting
Reads hurried supplier invoices, faded receipts, and pages that mix printed templates with handwritten figures, returning the numbers and line items exactly as written so you can check them.

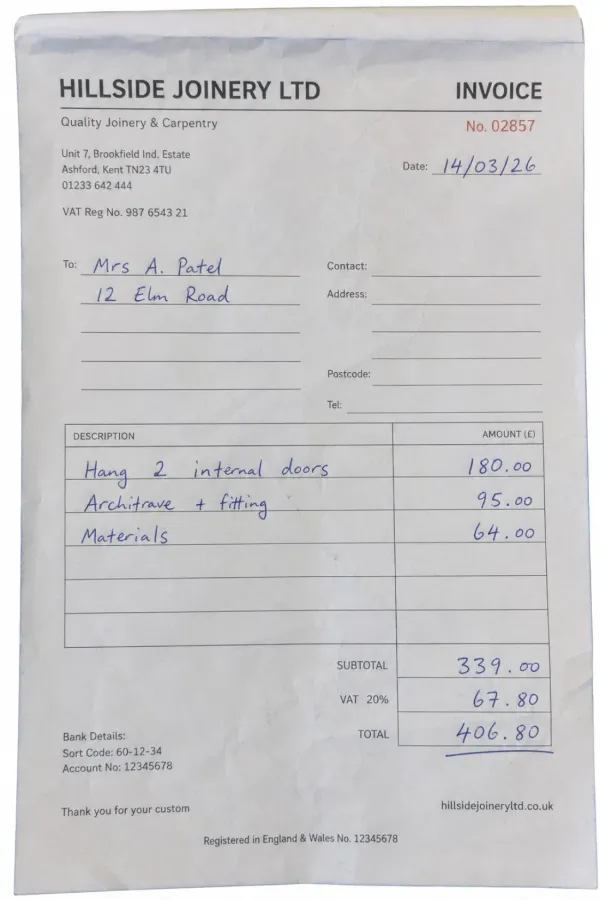
Handwriting OCR turns handwritten invoices, receipts, and expense claims into accurate text and structured data, including the rushed, part-printed paperwork that defeats ordinary OCR.

Loved by finance teams and field businesses
From bookkeepers and insurance agents to event teams turning a stack of forms into a spreadsheet.
"My assistant used to spend two or three hours keying handwritten forms into a spreadsheet and then our CRM. Now it works wonderfully and is so easy to use. My assistant is happier and so am I."
"I used it to turn a handwritten contents inventory for an insurance claim into a spreadsheet I could drop straight into Excel. It worked great."
"The free trial let me test a custom extractor on our handwritten registration forms and confirm the accuracy before committing. It was great, and I'll be using it for our next event."
How it works
Whether it's a single receipt or a batch of supplier invoices, the workflow is the same three steps: upload, let the AI transcribe, then export and use. There's nothing to install and nothing to train, so most people are set up and getting results within minutes.
 1
1 Drop in a photo or PDF, from a phone snap of a receipt to a batch of scanned supplier invoices. No format conversion or preprocessing needed.
 2
2 Our model transcribes invoices, receipts, and pages that mix printed templates with handwriting, reading the figures and line items and preserving the structure of the page.
 3
3 Download editable text in Word, Markdown, or plain text, or pull named fields and tables into a spreadsheet, then search across an entire set of documents in seconds.
Why finance teams and bookkeepers choose Handwriting OCR
Most OCR was built for clean printed text. Handwriting OCR reads real handwritten financial paperwork accurately, keeps it private, translates where you need it, and hands back searchable text and structured data in seconds.
Reads hurried supplier invoices, faded receipts, and pages that mix printed templates with handwritten figures, returning the numbers and line items exactly as written so you can check them.
Documents are encrypted in transit and at rest and processed only to return your results. Nothing is shared and nothing is used to train AI models, so your financial detail stays yours.

Define the fields you want, such as vendor, date, total, and tax, and pull them, plus line-item tables, straight into a spreadsheet as XLSX, CSV, or JSON.

Turn a receipt or invoice in another language into readable English in the same step, useful for overseas suppliers and travel expenses.

Supplier & vendor invoices
Turn handwritten and part-printed supplier invoices into editable text and structured fields, so vendor, dates, line items, and totals come off the page ready to check, instead of being retyped by hand.
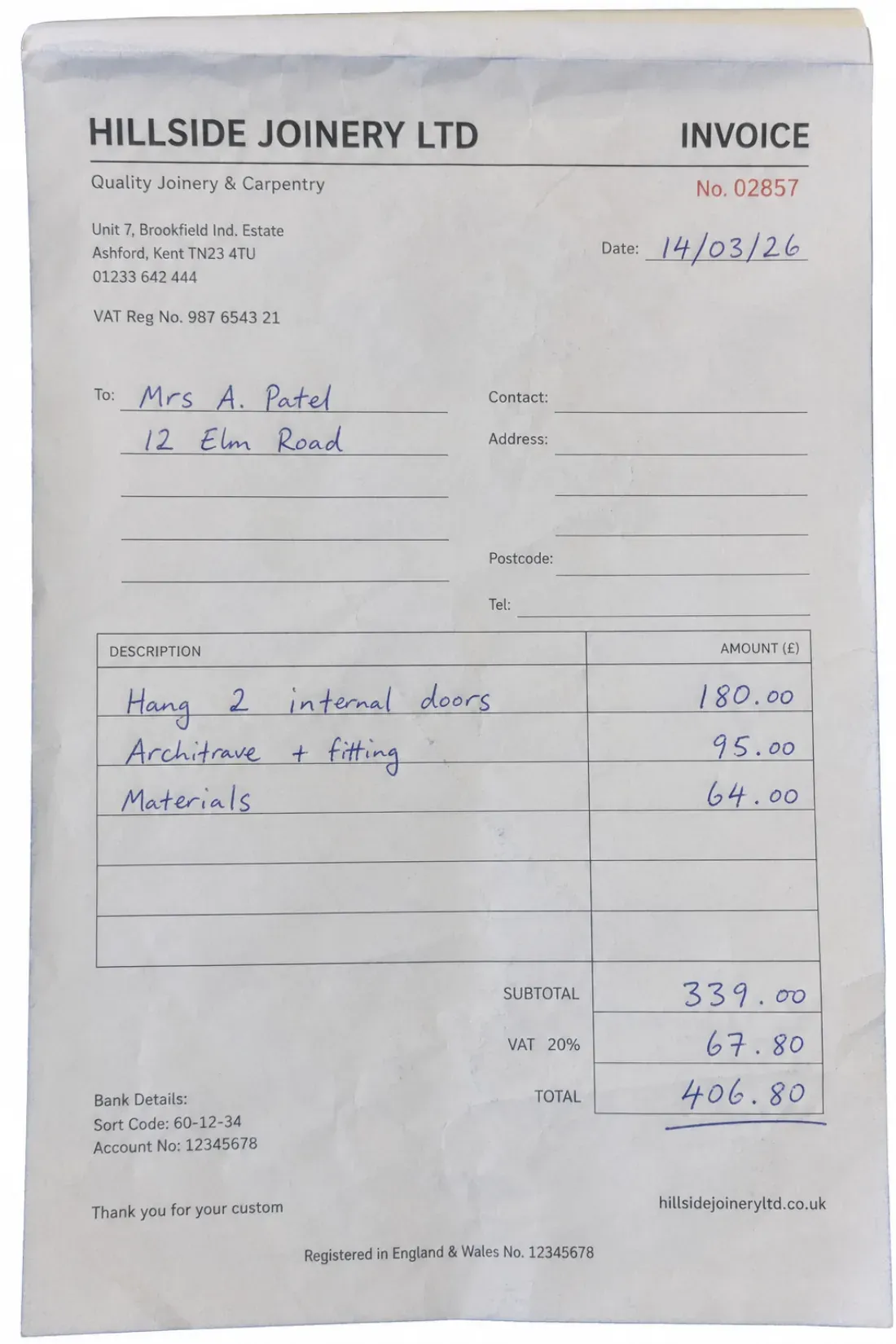
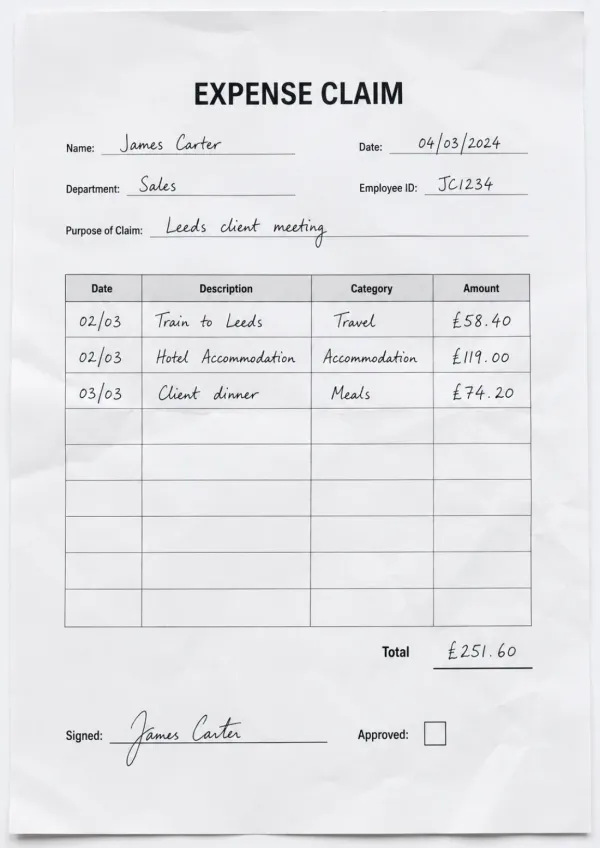
Receipts & expense claims
Lift merchant, date, and total off receipts and expense claim forms, including the handwritten notes people add, so a shoebox of receipts becomes a tidy expense report instead of an evening of typing.

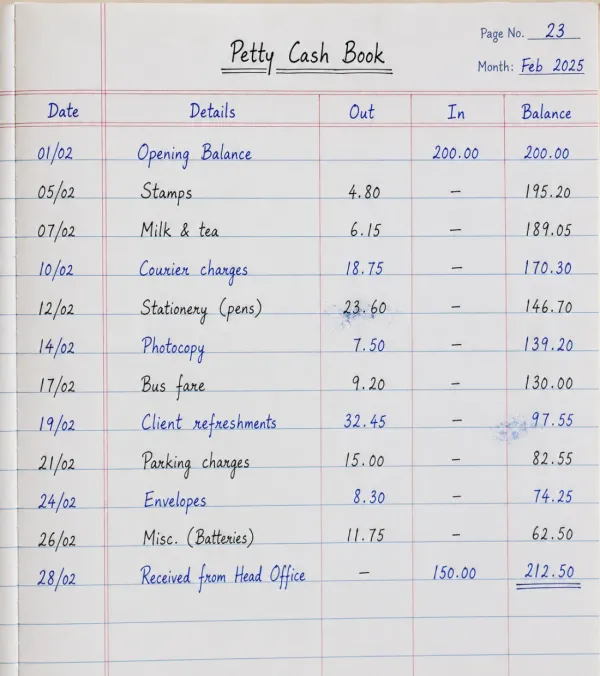
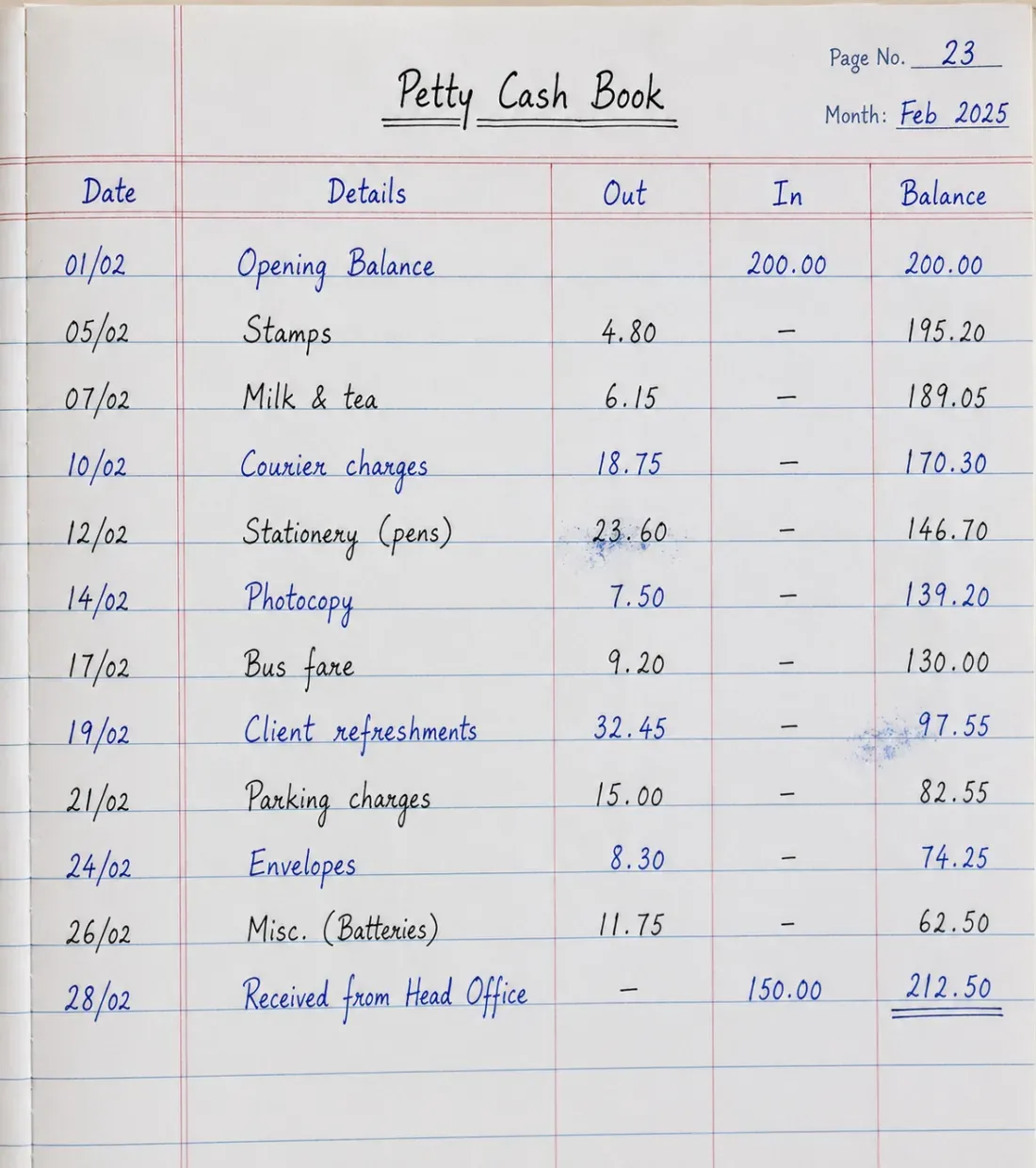
Petty cash & expense logs
Turn petty-cash books, mileage logs, and expense ledgers into clean rows you can total and analyse, with dates, descriptions, and amounts kept in order down the page.
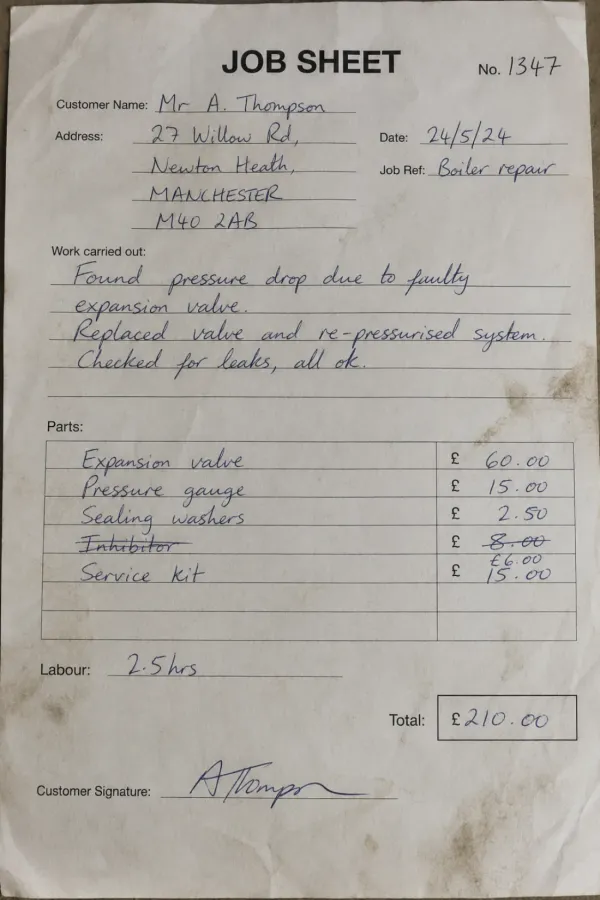
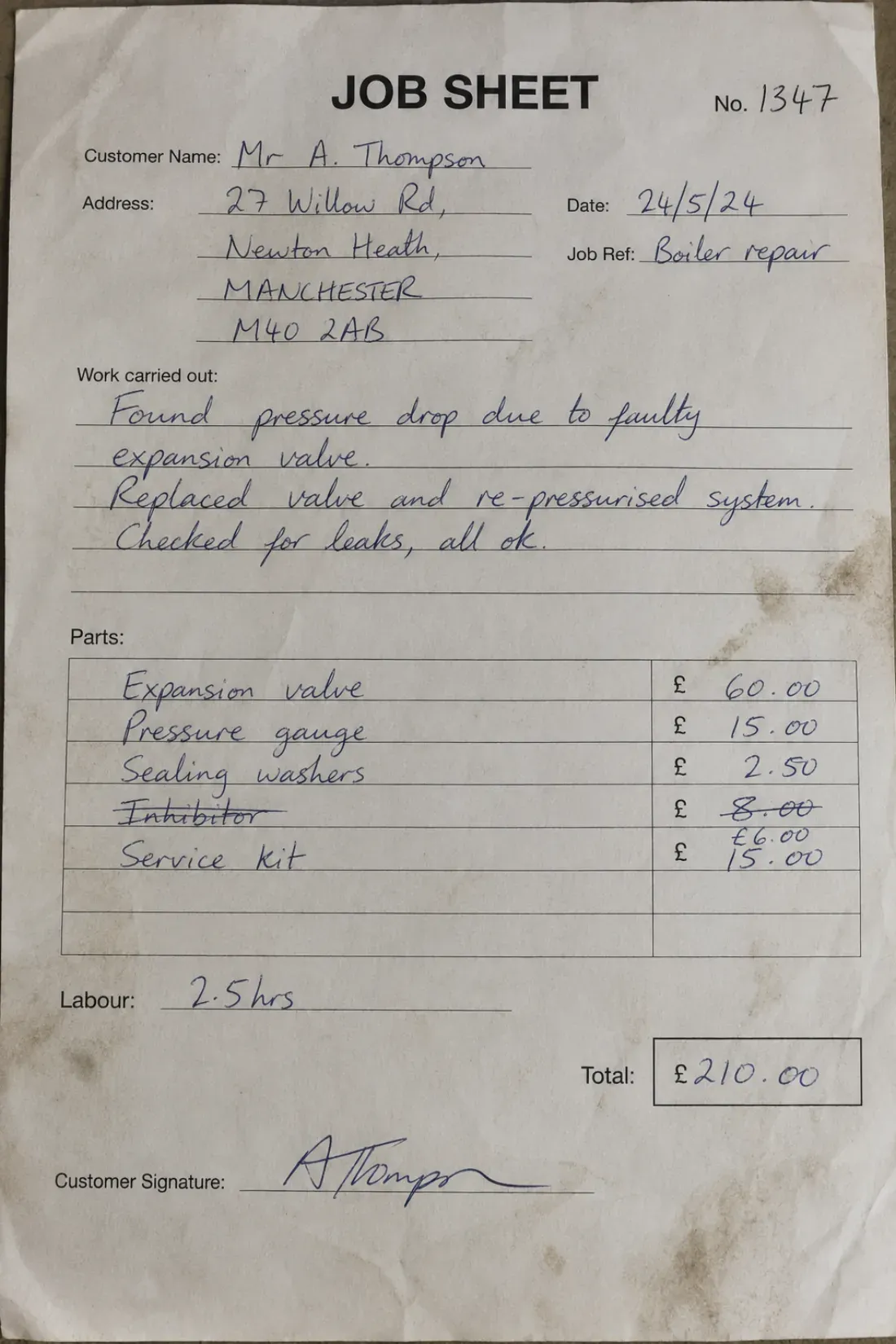
Delivery notes, job sheets & timesheets
Job sheets, delivery notes, and timesheets come back from the field in every hand imaginable. Handwriting OCR reads the quantities, hours, and notes so the day's paperwork is searchable and ready to bill.
Pricing
Pay-as-you-go credits or monthly subscriptions. Cancel any time.
No commitment
One-time purchase. Valid for 1 year.
250 pages / month
Billed monthlyBilled annually
1,000 pages / month
Billed monthlyBilled annually
10,000 pages / month
Billed monthlyBilled annually
For higher volumes, options for offline deployment, or any other custom requirements, please contact us.
FAQ
Any other questions? Get in touch and we'll answer right away.
Handwriting OCR is an AI service that turns handwritten documents into accurate, searchable, editable text. Unlike traditional OCR, which was built for printed text, it is built specifically for handwriting, including cursive, faded ink, historical scripts, and many languages, and it can translate non-English records into English in the same step. Upload a scan or photo and you get back clean text you can search, edit, and export to Word, Markdown, or plain text.
Handwriting OCR was founded in London in 2023, dedicated to applying modern AI to read the hardest handwritten documents: the cursive, faded, and historical pages that traditional OCR cannot handle. We are a small, independent UK team, the people who build the product also handle support, and we never use your documents to train models or share them with anyone.
It reads them well. Handwriting OCR transcribes handwritten and part-printed invoices, receipts, and expense forms, capturing vendor names, dates, line items, and totals as written. It identifies what is on the page without doing your accounting, so a digitized invoice is best treated as a fast, searchable first pass whose figures you check against the original. We do not return confidence scores, so verifying the numbers that matter is a human step by design.
Yes. On the Pro and Business plans, custom extractors let you define the fields you want, such as vendor, date, total, tax, or category, and pull them off invoices and expense forms into a spreadsheet (XLSX, CSV, or JSON). Table extraction does the same for tabular records like ledgers and line-item lists. For pages that mix a printed template with handwriting, transcription keeps the printed prompts and the handwritten answers together so it stays clear what was added by hand.
Not directly. Handwriting OCR hands back text and structured data (XLSX, CSV, or JSON) and offers an API on every plan, so you import the results into your accounting or ERP system, or build your own integration. We do not provide native connectors to accounting software, and we do not post invoices, match purchase orders, or process payments. We turn the handwriting into clean data; what you do with it stays in your systems.
Accuracy depends on how legible the original is. If you can read it, the system usually can, and a clearer scan always helps. Faded thermal receipts and poor phone photos are the hardest cases, so 300 DPI scans (or well-lit, in-focus photos) give the best results. Where a section is too far gone to read with confidence, check it against the original.
Yes. Part-printed invoice pads, delivery notes, and expense forms, where a printed layout is completed by hand, are among the most common documents we see. Transcription keeps the printed prompts and the handwritten entries together so the page stays clear, and custom extractors can pull the handwritten fields you care about into a spreadsheet.
Yes. Handwriting OCR processes handwriting across more than 300 languages and can translate non-English pages into English in the same step, which suits overseas suppliers, travel expenses, and multilingual records. Accuracy on unfamiliar scripts depends on handwriting clarity and script complexity, so testing with a sample page is the best guide for your documents.
Your documents remain private and are processed only to deliver results to you. They are encrypted in transit and at rest, not used to train AI models, not shared with third parties, and not retained longer than you choose (auto-delete is configurable from 15 minutes up to 14 days). Privacy is built into the service design as a fundamental principle, not an optional feature.
For organizations with formal requirements, the Business plan includes a GDPR Data Processing Agreement, a security documentation packet for procurement reviews, team access with admin controls, and audit logging. EU customers can choose EU-only data residency. We do not hold SOC 2 or ISO 27001 certification and do not offer HIPAA compliance. If your organization has specific data-protection needs, get in touch and we can talk through exactly how processing works.
Try it on your own documents
Upload a supplier invoice, a stack of receipts, or a job sheet and see how the transcription and field extraction compare to keying it in by hand. Your documents stay private and are never used to train models.

Our experience
Invoices, receipts, and expense paperwork are some of the most practical things people send us: fast, abbreviated, and written in a hurry on whatever pad was to hand. It is exactly the kind of document our handwriting OCR was built for, and we are honest about where it saves you time and where a person still has to check the figures.
A handful come up again and again:
By some distance, the request is the same: get it into a spreadsheet. A handwritten contents inventory, a batch of registration forms, a month of receipts, people want the figures and fields as rows they can total and analyse, not a wall of text to retype. That is what table extraction and custom extractors are for (on Pro and above): you define the fields you care about, such as vendor, date, total, and category, and our handwriting recognition returns them as XLSX, CSV, or JSON. For pages that mix a printed template with handwriting, transcription keeps the printed prompts and the handwritten answers together so it stays clear what was added by hand.
Every set of paperwork is different, so the only real test is your own. Try it on a few invoices or a stack of receipts before committing to a larger project, with free trial credits and no card required.