Quick Takeaways
- Handwriting OCR can process military records from different conflicts and time periods, handling various military clerks’ handwriting and service documentation formats
- It converts handwritten service details, unit assignments, pension claims, and muster information into searchable text for faster genealogical research
- Produces editable output that you can search across multiple service records, copy into research databases, and organize systematically
- Works with scanned images from National Archives, fold3, military repositories, or personal archive copies without requiring format conversion
- Manual verification is essential for military abbreviations and unit designations, but the technology accelerates the process of making service records accessible
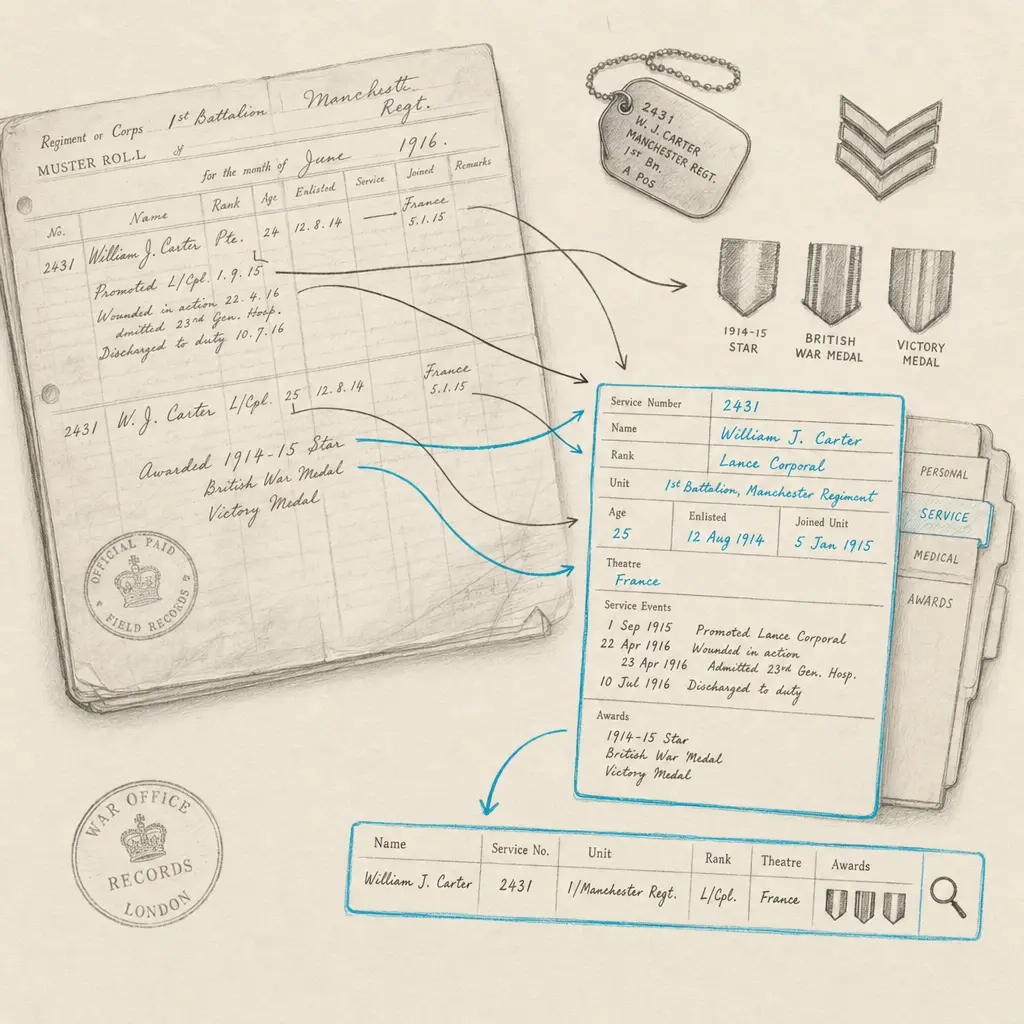
Military service records form crucial evidence in genealogical research. These documents prove where ancestors served, when they enlisted, which units they joined, what ranks they achieved, and often where they were at specific points in history. For family historians, military records provide not just service verification but also pension applications with family details, disability claims with medical histories, and compiled service records that track movements across campaigns.
But accessing the information in military records often means working through hundreds of pages of handwritten documentation. Most genealogists know the experience of reviewing compiled service files page by page, deciphering clerks’ handwriting, interpreting military abbreviations, and hoping to extract the service timeline that explains when and where your ancestor served.
Even when military records are digitized and available through the National Archives, fold3, or military repositories, they typically exist only as scanned images. You can view them, but you can’t search within the handwritten text itself. Finding specific unit assignments, discharge details, or pension claim information requires manual page-by-page review of service files that may span dozens or hundreds of pages.
This creates research friction that every military genealogist recognizes. You spend hours visually scanning service records. You manually transcribe pension applications into research logs. You can’t quickly search your collected military documents for all mentions of a particular unit, location, or disability claim because the handwritten text isn’t searchable.
This page explains what handwriting OCR can and cannot do for military genealogy research. It’s not about replacing careful source analysis or eliminating the need to verify service details against multiple records. It’s about understanding whether this type of tool can accelerate the mechanical work of extracting text from military documents so you can spend more time on genealogical analysis and less time on manual transcription.
Why Military Records Present OCR Challenges
Military service records were created across different conflicts, time periods, and administrative systems. This process created documents with characteristics that make automated text extraction challenging.
Military handwriting varies by clerk, branch of service, and historical period. Some military clerks maintained meticulous penmanship, producing service records that remain clearly legible generations later. Others processed paperwork under field conditions or during periods of heavy administrative load, creating entries where abbreviations are cryptic and handwriting is rushed. A single soldier’s compiled service file might contain documents from multiple clerks, each with different handwriting styles.
Different conflicts used different documentation systems and formats. Revolutionary War records look fundamentally different from Civil War compiled service records, which differ again from World War I draft registrations. Each military era developed its own administrative conventions, abbreviation systems, and documentation requirements that affected how information was recorded.
Microfilm and archive preservation introduced additional challenges. Many military records were microfilmed during mid-20th-century preservation efforts. These microfilm copies can show grain, contrast variations, and sometimes blurring that degrades the clarity of the original handwriting. Digital scans of these microfilms inherit these quality issues. Some records exist only as photocopies of photocopies, each generation degrading clarity further.
Military terminology and abbreviations compound the complexity. Service records use specialized military vocabulary, unit designations, rank abbreviations, and administrative codes that vary by time period and branch of service. A pension application might reference “Co. K, 15th Reg’t N.Y. Vol. Inf.” with the expectation that readers understand military organizational structure. Medical disability claims use terminology specific to military medicine of that era.
Characteristics that make military OCR challenging:
- Variable clerk handwriting: Different individuals with different handwriting quality within a single service file
- Historical cursive penmanship: Flowing connected writing styles typical of 19th and early 20th century military clerks
- Military abbreviations: Service-specific shorthand for ranks, units, locations, and administrative categories
- Form-based layouts: Information organized in pre-printed forms with handwritten entries that must maintain structure
- Microfilm degradation: Grain, contrast issues, and quality loss from preservation copying
- Multi-document files: Compiled service records containing different document types from different periods with different formats
- Field conditions: Some records created under combat or deployment conditions with rushed handwriting and minimal standardization
What Handwriting OCR Can Extract from Military Records
Handwriting recognition technology designed for historical documents approaches military records differently than standard OCR. It’s built to handle the variable handwriting, specialized terminology, and preservation challenges typical of actual military genealogy research.
Service Record Information
The core value of military OCR is extracting text from service documents so it becomes searchable and editable. Instead of looking at a compiled service file as a collection of fixed images, you get the actual text: names, dates, unit assignments, rank changes, locations, and other recorded service details.
This means you can search extracted military records for specific unit designations, locate all mentions of particular battles or campaigns, or find disability claims referencing specific conditions. You can copy service dates and locations directly into genealogy software or research databases without manual retyping.
The technology preserves document structure where possible, maintaining the relationship between form labels and handwritten entries. This helps preserve context during extraction.
Pension Applications
Military pension applications often contain rich genealogical information beyond basic service verification. Applicants provided birth dates, marriage information, children’s names, residence locations, and disability details. Widow’s pensions included marriage dates and places, children’s ages, and family composition at the time of application.
Handwriting OCR processes these narrative sections, converting the handwritten testimony and supporting affidavits into searchable text. This makes it easier to extract family details that might otherwise require complete manual transcription of lengthy applications.
Muster Rolls and Unit Records
Muster rolls document which soldiers served in particular units at specific times. These records typically list names, ranks, and status (present, absent, detached, deserted, etc.) in columnar format.
Handwriting OCR handles these structured lists, maintaining the relationship between soldier names and their status entries. This allows searching across muster rolls for specific individuals or tracking unit composition changes over time.
Medical and Disability Records
Service files often include medical examination reports, disability claims, and hospital records. These documents use medical terminology of their era and describe conditions, treatments, and service-connected disabilities.
The technology processes these medical narratives, extracting the handwritten descriptions that support pension claims or document treatment during service. While medical terminology may require researcher interpretation, having searchable text accelerates the process of finding relevant medical information within large service files.
Correspondence and Supporting Documentation
Compiled service records often contain letters, affidavits from fellow soldiers, and administrative correspondence. These documents provide context about service conditions, explain gaps in official records, or offer testimony supporting pension claims.
Handwriting OCR converts these narrative documents to searchable text, making it possible to find specific references to events, locations, or individuals mentioned in supporting documentation.
What to Expect: Accuracy and Limitations
Understanding what handwriting OCR handles well and where it needs verification helps set realistic expectations for military genealogy applications. This isn’t technology that eliminates the need for source verification or military knowledge. It’s a tool that accelerates text extraction so you can focus on genealogical analysis and service reconstruction.
The table below shows typical performance with different military record elements:
| Record Element | What Works Well | What Requires Verification |
|---|---|---|
| Names | Standard soldier names, clearly written entries | Unusual surname spellings, names written by hearing during oral testimony |
| Dates | Service dates, enlistment and discharge information | Dates with unclear month abbreviations, dates written in various formats |
| Units | Complete unit designations written clearly | Heavily abbreviated unit names, informal unit references, reorganized unit designations |
| Ranks | Common rank names that appear repeatedly | Abbreviated ranks, brevet ranks, temporary rank assignments |
| Locations | Standard geographic names, major battle sites | Variant place spellings, military camp names, informal location descriptions |
| Medical conditions | Common injury descriptions, standard disability terminology | Archaic medical terms, heavily abbreviated condition descriptions, diagnostic terminology of the era |
What Handwriting OCR Handles Well
Standard service information that repeats across military documents processes reliably. Names, dates of service, basic unit assignments, and common rank designations that appear in standardized formats benefit from pattern recognition across similar documents.
Clearly written pension narratives from applicants who wrote carefully produce accurate extractions. Some pension applications contain detailed personal narratives about service experiences, family circumstances, and disability claims written in clear handwriting that processes well.
Complete service documents with standard military form formats extract more reliably than partial documents or informal field notes. When military clerks followed established documentation procedures and used standard forms, the output maintains that structure.
What Requires Manual Verification
Military abbreviations benefit from researcher interpretation, especially for units and locations. A unit designation abbreviated as “Co. K, 15th N.Y. Vol.” might extract accurately, but understanding what this means requires military organizational knowledge. Researchers familiar with Civil War unit structures can interpret these; automated processing alone cannot.
Medical terminology from historical military medicine needs contextual interpretation. A disability described as “rheumatism” in an 1880s pension claim might appear accurately in extracted text, but understanding what this meant in terms of service-connected disability requires knowledge of medical practice and pension claim standards of that era.
Rank changes and temporary assignments may require verification against other sources. If a service record shows conflicting rank information or brevet rank assignments, the extracted text will reflect what’s written, but determining actual rank at specific times requires researcher analysis across multiple documents.
Location references, especially for military camps and temporary installations, benefit from historical military knowledge. A reference to “Camp near Fredericksburg” in a letter might extract accurately, but identifying exactly where and when this was requires understanding of campaign chronology and military movements.
The goal is acceleration, not elimination of research work. Handwriting OCR handles the mechanical task of text extraction from military documents. Researchers apply their expertise to verify accuracy, interpret military terminology, and reconstruct service timelines based on the extracted information.
How Military Genealogists Use Handwriting OCR
Handwriting OCR addresses specific bottlenecks in military research workflows. It’s not a replacement for careful source analysis or understanding of military history. It’s a tool for removing friction from the process of extracting and organizing military service information.
Common military genealogy applications:
Processing Compiled Service Files
Compiled military service files (CMSRs) from the National Archives often contain dozens or hundreds of pages documenting a single soldier’s service. These files combine muster rolls, service cards, medical records, and administrative documents, all potentially in different handwriting.
Handwriting OCR converts entire compiled service files to searchable text. Instead of manually reviewing every page looking for specific information, you can search the extracted text for unit transfers, medical events, or administrative actions. This accelerates the process of building complete service timelines from fragmented documentation.
Extracting Pension Application Details
Military pension applications contain valuable genealogical information beyond service verification. Applicants provided family details, residence information, and personal narratives about service and disabilities. Widow’s pensions documented marriages and family composition.
Rather than manually transcribing lengthy pension applications, you can process them and extract the relevant family information directly. This is particularly valuable for pension files that span many pages with supporting affidavits and correspondence.
Building Unit Rosters
Researchers studying particular military units often need to compile rosters from muster rolls, service records, and unit documentation. Manually transcribing hundreds of names from multiple muster rolls is time-consuming work.
Handwriting OCR accelerates roster compilation by extracting names and service information from muster rolls and unit records. You can then organize and verify this information to build comprehensive unit databases.
Searching for Battle and Campaign References
Military service records often mention specific battles, campaigns, or military actions. Finding these references by manually reviewing every page of a service file or pension application is slow work.
With searchable extracted text, you can search for battle names, campaign references, or geographic locations across entire service files. This helps identify relevant sections that document participation in specific military actions.
Verifying Service Against Multiple Sources
Military genealogy best practices involve verifying service details against multiple sources. Enlistment records, muster rolls, discharge papers, and pension applications should corroborate each other, but inconsistencies sometimes appear.
Having searchable text from all these sources makes it easier to compare details, identify discrepancies, and track down documentation that explains variations in dates, units, or service circumstances.
Creating Research Databases
Many military genealogists maintain detailed databases documenting soldiers from particular units, battles, or family lines. Building these databases traditionally requires extensive manual transcription from service records.
Handwriting OCR accelerates database building by providing editable text that can be verified and organized into database structures. This reduces data entry time and minimizes transcription errors introduced during manual typing.
Organizing Personal Archive Collections
Researchers who have collected service records for multiple ancestors or an entire family line benefit from making their entire collection searchable. Rather than remembering which ancestor’s file contains specific information, you can search across all your processed military documents.
This is particularly valuable for researchers working on multi-generational military service or tracking family military participation across different conflicts.
Integration with Military Research Workflows
Handwriting OCR fits into existing military genealogy workflows as a text extraction tool rather than replacing established research practices. Understanding where it fits helps determine whether it addresses bottlenecks you actually experience.
Typical workflow integration:
- Locate military records using pension indexes, service databases, or compiled military service file (CMSF) collections
- Download or save record images from National Archives, fold3, state archives, or other military repositories
- Process record images through handwriting OCR to extract text
- Verify extracted information against the original images, checking names, dates, units, and service details
- Copy verified data into genealogy software, military databases, or research timelines
- Search extracted text for units, battles, locations, or medical conditions across multiple service documents
- Cite sources properly in your research, referencing the original military records not the extracted text
The technology handles step 3, accelerating text extraction. The other steps remain researcher work that requires military knowledge and careful source analysis.
For researchers working extensively with compiled service files or lengthy pension applications, the time savings can be substantial. Instead of manually transcribing hundreds of pages, you extract the text and spend your time on verification and service reconstruction.
For researchers who primarily work with brief service records or well-indexed databases, the value is more situational. When you encounter complex pension files, need to search for specific battle references, or want to build comprehensive unit databases, handwriting OCR provides capabilities you wouldn’t otherwise have without extensive manual transcription.
Getting Started with Military Record OCR
If you’re working with military records and wondering whether handwriting OCR would accelerate your research, the most direct approach is to test it with actual military documents from your current research.
Military handwriting varies by conflict, time period, and administrative system. A Revolutionary War pension application looks different from a Civil War compiled service file, which differs from a World War I draft registration. The only way to know if handwriting OCR will help with your specific military research is to try it with the kinds of documents you actually work with.
Handwriting OCR offers a free trial with credits you can use to process sample military records. Download a page from a pension application you’ve been meaning to transcribe, a section from a compiled service file, or a muster roll where you need to extract soldier names. Process it and compare the extracted text to what you’d get from manual transcription.
Your military documents remain private throughout this process. They’re processed only to deliver results to you and are not used to train models or shared with anyone else. Military records often contain personal information about ancestors and family members, and privacy is built into the service design.
The process is straightforward. Upload your military record image or PDF, process it, and download the results as editable text in formats that work with your research workflow (Word, Markdown, plain text, or structured data formats). There’s no software installation, no technical setup, and no commitment required to test whether it works for your military documents.
If it saves you time on the military records you tested, it will likely save time on similar materials in your research. If it doesn’t meet your accuracy needs for specific conflict periods or record types, you’ve learned that before investing further. Either way, you’ll have a clearer understanding of where handwriting OCR fits in military genealogy workflows.
For broader context on how handwriting OCR works across different genealogical document types beyond military records, see our main page on genealogy and family history handwriting OCR.
Frequently asked questions
Can handwriting OCR accurately read military records from different conflicts like Revolutionary War, Civil War, or World War I?
Yes. Handwriting OCR is designed to process military records from different time periods and conflicts, handling the various cursive styles and documentation formats used across different military eras. Each conflict period used different administrative systems and documentation conventions, and military clerks wrote in the penmanship styles typical of their era. The technology adapts to these variations. Accuracy depends on the individual clerk's handwriting quality and the condition of the military record image you're working with. The best way to assess performance on records from your specific conflict period is to test with sample pages from the military documents you're actively researching.
Will handwriting OCR work with military records downloaded from the National Archives, fold3, or other military repositories?
Yes. Handwriting OCR processes military record images regardless of their source. If you can download a service record from the National Archives, fold3, state military archives, or other digital repositories, you can process it. The system handles various image qualities and formats, including downloads from military genealogy platforms, scans from microfilm, or photographs of military records from archive visits. No format conversion or special preparation is required before processing.
How does handwriting OCR handle military abbreviations and unit designations?
Handwriting OCR extracts military abbreviations and unit designations as they actually appear in the records. If a service record lists a unit as "Co. K, 15th Reg't N.Y. Vol. Inf.," the system extracts that abbreviated form. This preserves the historical military terminology used in the original documents. However, interpreting what these abbreviations mean—understanding unit organization, identifying specific regiments, or tracking unit reorganizations—remains researcher work. The technology handles text extraction; military historical knowledge is required for interpretation.
Can I use handwriting OCR to make entire pension files searchable for family details?
Yes. Many military genealogists use handwriting OCR specifically for this purpose. Military pension applications often contain rich genealogical information including family details, marriage information, children's names, and residence locations spread across many pages of narrative testimony and supporting documentation. By processing complete pension files, you create searchable text that you can search for specific family names, locations, or events rather than manually reviewing every page. This is particularly valuable for widow's pensions and disability claims that contain extensive family information.
Does using handwriting OCR mean my military research records are sent to third parties or used to train AI models?
No. Your military records remain private and are processed only to deliver results to you. They are not used to train AI models, not shared with third parties, and not retained longer than necessary to complete processing. This is particularly important for military research that may contain personal information about ancestors and family members. Privacy is built into the service design as a fundamental principle, not an optional feature.