Accuracy on clinical handwriting
Reads hurried notes, Latin shorthand, and pages that mix printed forms with handwritten answers, returning the text exactly as written so you can actually work with it.

Handwriting OCR turns handwritten clinical notes, prescriptions, and patient records into accurate, searchable text, including the rushed, abbreviated hands that defeat ordinary OCR.




How it works
Whether it's a single prescription or a batch of patient records, the workflow is the same three steps: upload, let the AI transcribe, then export and search. No setup, no training, and results in seconds.
 1
1 Drop in a photo or PDF, from a phone snap of a chart to a batch of scanned patient records. No format conversion or preprocessing needed.
 2
2 Our model transcribes clinical notes, prescriptions, and pages that mix printed forms with handwriting, reading the shorthand and abbreviations and preserving the structure of the page.
 3
3 Download editable text in Word, Markdown, or plain text, or pull named fields from forms into a spreadsheet, then search across an entire set of records in seconds.
Why clinicians and researchers choose Handwriting OCR
Most OCR was built for clean printed text. Handwriting OCR reads real clinical handwriting accurately, keeps it private, translates where you need it, and hands back searchable text and structured data in seconds.
Reads hurried notes, Latin shorthand, and pages that mix printed forms with handwritten answers, returning the text exactly as written so you can actually work with it.
Documents are encrypted in transit and at rest and processed only to return your results. Nothing is shared and nothing is used to train AI models, so patient information stays private.

Turn a handwritten record in another language into readable English in the same step, useful for international patients, referrals, and archived materials.

Get clean text out as Word, Markdown, or plain text, or use custom extractors and table extraction to pull named fields from forms straight into a spreadsheet.

Clinical notes & patient charts
Turn handwritten progress notes, charts, and observations into searchable text, with dated entries and the structure of the page kept intact, so a single note can be found across a whole chart in seconds.

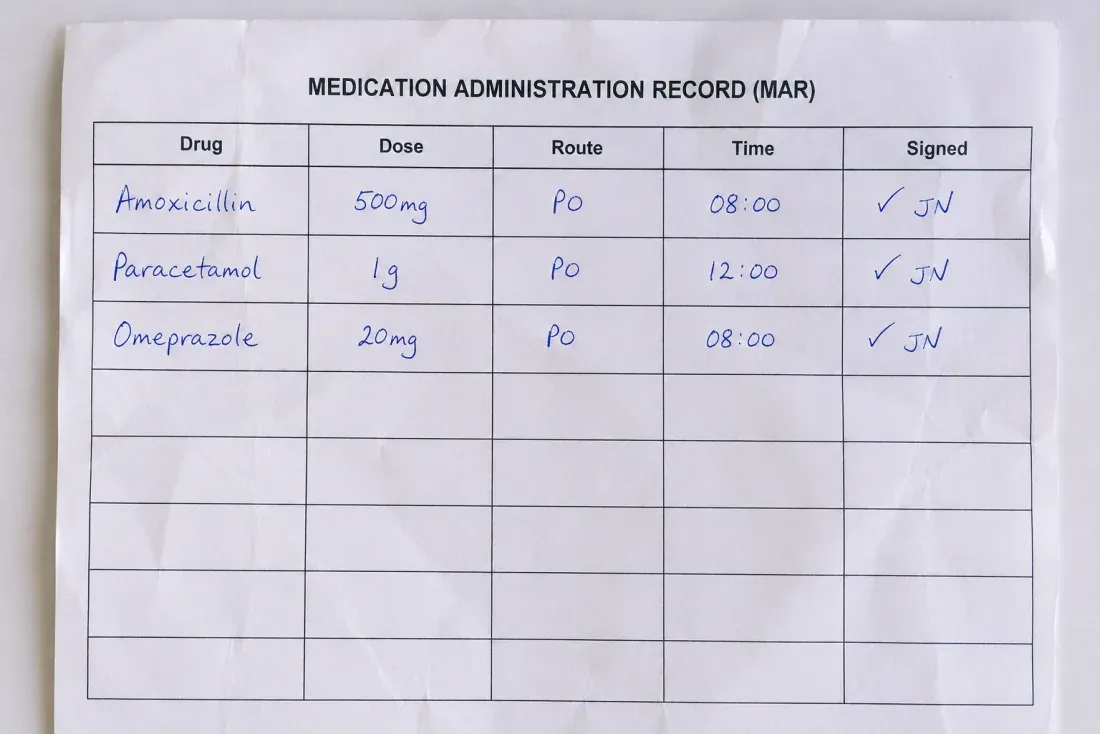
Prescriptions & medication records
Pull medication names, doses, routes, and timing off handwritten prescriptions and medication records into editable text you can search and check. The compressed Latin shorthand comes through as written.
Research & historical records
Turn archived case notes, admission registers, and historical clinical records into searchable, analyzable text, faded ink and period hands included, so a long-running archive can be studied at scale.

Intake & medical forms
Lift handwritten answers off intake forms and questionnaires while keeping the printed prompts clear, then pull the fields you care about into a spreadsheet with a custom extractor.

Pricing
Pay-as-you-go credits or monthly subscriptions. Cancel any time.
No commitment
One-time purchase. Valid for 1 year.
250 pages / month
Billed monthlyBilled annually
1,000 pages / month
Billed monthlyBilled annually
10,000 pages / month
Billed monthlyBilled annually
For higher volumes, options for offline deployment, or any other custom requirements, please contact us.
FAQ
Any other questions? Get in touch and we'll answer right away.
Handwriting OCR is an AI service that turns handwritten documents into accurate, searchable, editable text. Unlike traditional OCR, which was built for printed text, it is built specifically for handwriting, including cursive, faded ink, historical scripts, and many languages, and it can translate non-English records into English in the same step. Upload a scan or photo and you get back clean text you can search, edit, and export to Word, Markdown, or plain text.
Handwriting OCR was founded in London in 2023, dedicated to applying modern AI to read the hardest handwritten documents: the cursive, faded, and historical pages that traditional OCR cannot handle. We are a small, independent UK team, the people who build the product also handle support, and we never use your documents to train models or share them with anyone.
It reads them well. Handwriting OCR extracts medication names, dosages, routes, and timing from handwritten prescriptions and medication records, and transcribes clinical and progress notes including the Latin shorthand clinicians use. It identifies what is written without applying clinical judgment, so a digitized prescription is best treated as a fast, searchable first pass that a pharmacist or prescriber confirms against the original, never as the authoritative reading on its own.
Clinicians write constantly under time pressure and rely on a centuries-old Latin shorthand: "TID" for three times daily, "HS" for at bedtime, "PO" for by mouth, "PRN" for as needed. Volume and fatigue degrade legibility, and the compressed notation is unfamiliar to most readers. This combination of rushed handwriting and specialized abbreviations is exactly what Handwriting OCR is built to read, where generic OCR fails.
Yes. On the Pro and Business plans, custom extractors let you define the fields you want, such as name, date of birth, allergies, medications, or reason for visit, and pull them off intake forms and questionnaires into a spreadsheet (XLSX, CSV, or JSON). Table extraction does the same for tabular records like observation charts. For mixed pages, transcription keeps the printed prompts and handwritten answers together so it stays clear what was added by hand.
Handwriting OCR reads archived case notes, admission registers, and historical clinical records, and can translate non-English records into English in the same step, which suits research and archival projects. Accuracy depends on the condition of the document: very faded ink and the oldest hands are harder, and it performs most reliably on cursive from the 1940s onward. Testing a sample page is the best guide for a given archive.
Handwriting OCR processes handwriting across many languages and can translate non-English pages into English in the same step. It reads text based on what is actually written rather than expecting a single language throughout, which suits international patients, referrals, and multilingual archives. Accuracy on unfamiliar scripts depends on handwriting clarity and script complexity, so testing with a sample page is the best guide for your records.
Documents remain private and are processed only to deliver results to you. They are encrypted in transit and at rest, not used to train AI models, not shared with third parties, and not retained longer than necessary (you control retention, with auto-delete configurable from 15 minutes up to 14 days). Privacy is built into the service design as a fundamental principle, not an optional feature.
For organizations with formal requirements, the Business plan includes a GDPR Data Processing Agreement, a security documentation packet for procurement reviews, team access with admin controls, and audit logging. EU customers can choose EU-only data residency, and we can arrange region-specific residency as part of a custom package. We do not currently offer HIPAA compliance or sign Business Associate Agreements. If your institution has specific data-protection needs, get in touch and we can talk through exactly how processing works.
Try it on your own documents
Upload a prescription, a page of clinical notes, or an intake form and see how the transcription compares to retyping it by hand. Your documents stay private and are never used to train models.

Our experience
Medical handwriting is the use case people picture when they think of writing no one can read, and it is exactly the kind of document our handwriting OCR was built for: fast, abbreviated, and written under pressure. We are honest about where it helps and where a person still has to look.
By some distance, the questions we field most about medical records are about privacy and data residency, which is no surprise for documents that carry personal information. Our stance is the same for every account: documents are encrypted in transit and at rest, never used to train our models, never shared, and deleted on a schedule you control (from 15 minutes up to 14 days). For organizations that need their data to stay in a particular region, we can arrange data residency as part of a custom package.
A handful of document types come up again and again:
Faithful transcription matters more in clinical records than almost anywhere else. We return what is actually on the page rather than a tidied-up guess, because a dose or an abbreviation is not something to paraphrase. Our handwriting recognition is tuned to capture the page as written, shorthand and all. For forms, custom extractors (on Pro and Business) pull the named fields you define straight into a spreadsheet, so a stack of intake forms becomes structured data instead of retyping.
Every set of records is different, so the only real test is your own. Try it on a page or two of your hardest handwriting before committing to a larger project, with free trial credits and no card required.