Pay as You Go
No commitment
£15 $15 €15 / 100 pages
One-time purchase. Valid for 1 year.
- AI-enhanced formatting
- Export to Markdown (plain text)
- Export to Microsoft Word
- Two-factor authentication
- API access
- No commitment
- Valid for 1 year
Turn any image into text, including the handwriting other converters can’t read.
Photos, scans, screenshots, PDFs. Upload an image and get clean, editable text back in seconds. Most image-to-text tools only handle printed text. Handwriting OCR was built for the hard images too: cursive, messy notes, and old documents.



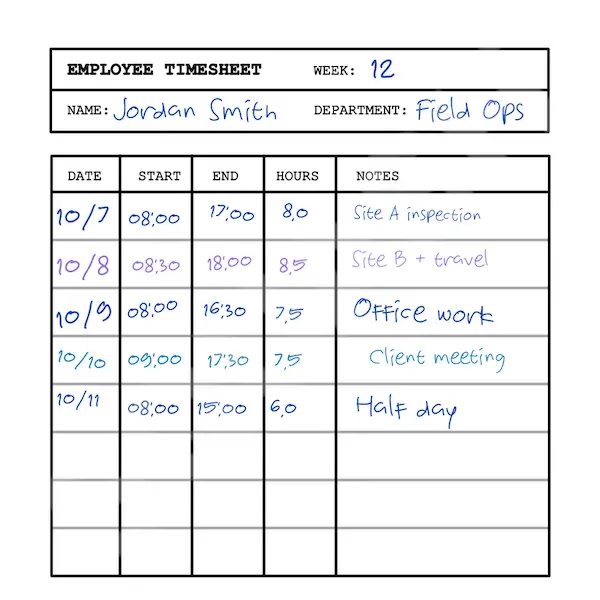



Where image-to-text tools differ
For a clean screenshot or a typed page, almost any OCR tool works. The real divide is handwriting, and that is what Handwriting OCR is built for.
'Typical image-to-text tools' means free online converters and built-in phone OCR (e.g. Apple Live Text, Google Drive OCR), which are optimised for printed text. Capabilities current as of June 2026.
A real photo, not a clean scan
We took one of the messiest journal photos people have shared online, ran it through a typical handwriting scanning app and through Handwriting OCR, and put the raw output side by side. No cleanup, no cherry-picking.
 Click to enlarge
Click to enlarge Jan 26 2018
Classes have started back up. Not too bad so far, just trying to keep on top of things. Going to work on a paper tomorrow, hopefully I can get my brain in gear. I don't know why, but it's just been a desert lately. Nothing forms, just a wasteland, but I guess even a wasteland eventually blooms life. Just need to fight through this funk or find some sort of inspiration. Why does my pen always fade? Is it the way I got to write? Or the pen itself? Maybe I'll try to use those art pens to add more color to these pages.
Work was pretty boring, not much happened. Just was talking to my coworker about schooling and my "best friend" just med until she needs me abandoning was to think about cutting her out, because she isn't doing it maliciously, just doesn't really listen when both Mom and I tell her "hey, you can't just drop your friends like that", but oh well...
ganze 2016 Classes have started back up. Not too bad Di wat things. trying to Sounes to keep on top work on iper tomorrow hopefully + canget my brain is gear & don't know why, but its deser just been a lately. Nothing wasteland Just even wasteland eventuale life. Ris funk or need to fight my guess Obloany through one 500 en always ade vay & got to write? sen those or e color Work was maybe D' art pers to the Zetty the Of the try to adc Dags boring not much happened talking 10 aworker about ny "best friend" jest ne until Shooting and She needs m abandoning ts, DO because to think about cutting her out she isn't doing just doesn't really booth MomandA can't just drop your friends oh well. it maliciously lister when Stall here "hey, you like that, fine DE does my
Notes
Source: Original image: r/Journaling. Run through both tools, June 2026.
Any image, any source
Snap a photo of a letter, scan a page, screenshot a document, or drop in a multi-page PDF. The AI handles uneven lighting, phone-camera angles, and mixed pages of handwriting and print. Upload many files at once and come back to finished text.
The hard part
A photo of a typed page is easy. A photo of someone's handwriting is where ordinary image-to-text tools fall apart. Handwriting OCR is trained specifically on handwritten images, so cursive, connected letters, faded ink and older hands come back as real text, not garbled fragments.
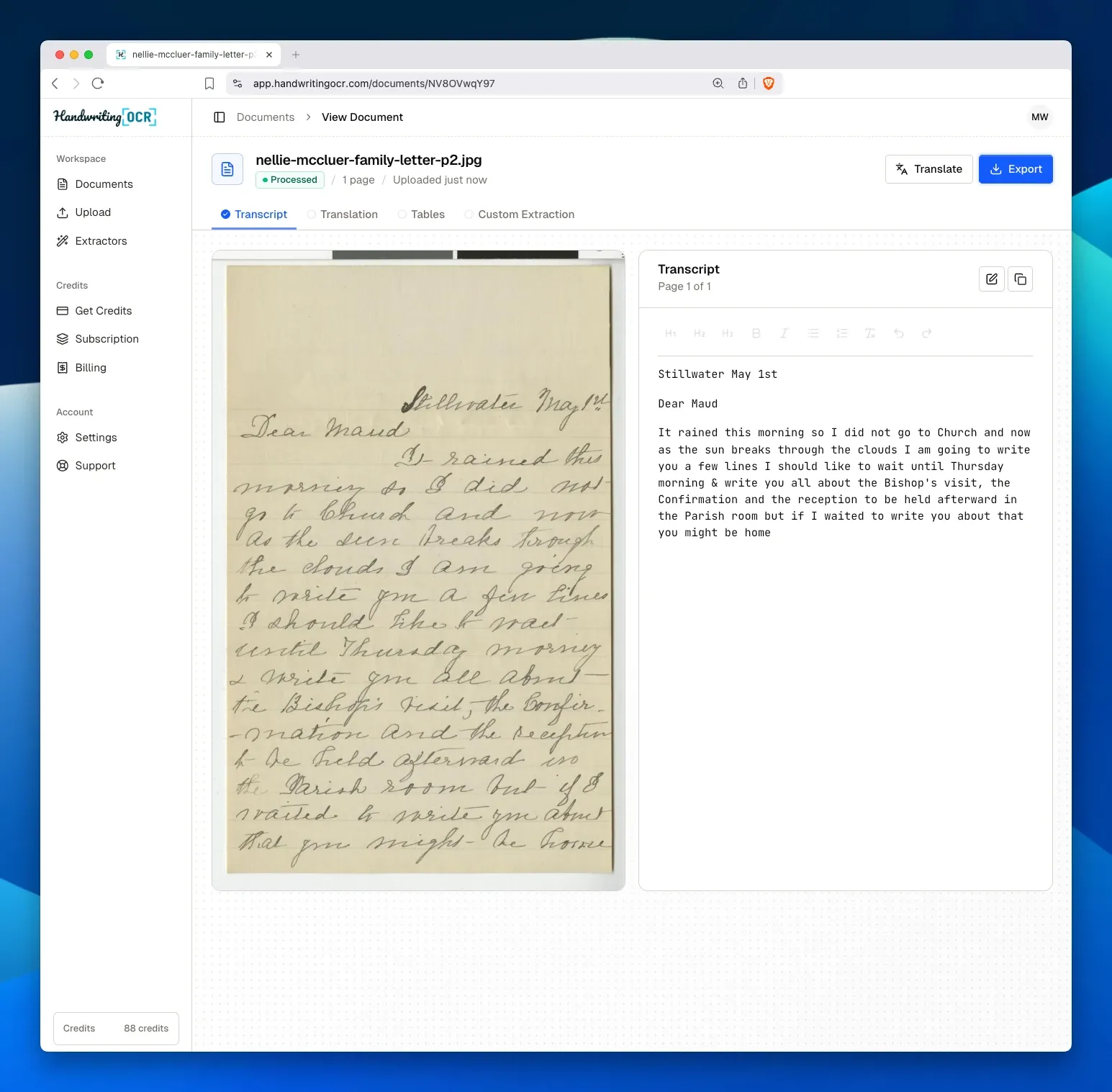
From people who tried the other tools first
"I'd tried Google Lens, Transkribus and Pen2Text. Handwriting OCR has by far the best transcription, and it's not even close."
"I uploaded two images of an 1820 will and was totally impressed, 80 to 90% accuracy on a 200-year-old hand."
"I tried it on a messy page of my college notes. It was by far and away the clear winner, extremely accurate."
Private by default
Files are encrypted in transit and at rest, never used to train our models, and auto-deleted on a schedule you set (default 7 days, anywhere from 15 minutes to 14 days).
Read it in any language
Extract text from an image in French, German, Spanish or any of 300+ languages, then translate it in the same workflow at no extra cost.
Use it your way
Get text back as Word, PDF, TXT or JSON. Need it in your own software? A first-party API is on every plan, including the free trial.
Being straight
If your images are clean and the text is typed, a free image-to-text tool will do the job and cost nothing. It is worth paying for Handwriting OCR when the image is harder than that.
Pricing
Pay-as-you-go credits or monthly subscriptions. Cancel any time.
No commitment
One-time purchase. Valid for 1 year.
250 pages / month
Billed monthlyBilled annually
1,000 pages / month
Billed monthlyBilled annually
10,000 pages / month
Billed monthlyBilled annually
For higher volumes, options for offline deployment, or any other custom requirements, please contact us.
FAQ
Anything else? Get in touch and we'll answer right away.
Upload PDF, JPG, PNG, GIF, HEIC or TIFF. Phone photos, flatbed scans, and screenshots all work. Multi-page PDFs are processed page by page in a single upload.
Yes, and that is the point. Most image-to-text converters are built for printed text and struggle on handwriting. Handwriting OCR is built specifically for handwritten images: cursive, messy notes, and historical hands, as well as printed text.
On clear printed text, accuracy is high, as it is with most OCR tools. The difference shows on handwriting, where general image-to-text tools, phone OCR like Apple Live Text, and Google Drive OCR fall behind. Accuracy depends on the original image, so the honest way to judge it is to run your own page on the free trial.
Text comes back as TXT, Word (DOCX), PDF or JSON. Tabular documents can be extracted to Excel on the Pro plan and up. You can also translate the extracted text into and out of 300+ languages in the same workflow.
New accounts start with free trial credits, no credit card needed, so you can convert a few images before paying. After that, pay-as-you-go is $0.15 per page (100 for $15) and subscriptions start at $19 per month.
Your files are encrypted in transit and at rest, are never used to train our models, and auto-delete on a schedule you control (default 7 days, configurable from 15 minutes to 14 days).
Try it on your own image
Bring the photo other converters couldn’t read.
Free trial credits, no credit card. Upload the image you’re stuck on and see the text come back in seconds.
Our experience
Most people who search for an “image to text” tool do not have a clean screenshot. They have a photo: a grandmother’s letter, a page of lecture notes, a form filled in by hand, an old record from an archive. Generic converters and phone OCR do a fair job the moment the text is neatly typed, and fall apart the moment it is not.
That gap, handwriting in a real-world photo, is the whole reason Handwriting OCR exists. We process thousands of these images every week: messy, faded, cursive, multi-page, in dozens of languages. The text above is one of them, run through a typical scanning app and through our own, with nothing cleaned up.
If you have an image you are stuck on, the fastest way to judge it is to try it free on that exact photo.